
ask.py: Perplexity like search-extract-summarize flow in Python
2024-09-15
With the new Llama 3.2 release, Meta seriously leveled up here — now you’ve got vision models (11B and 90B) that don’t just read text but also analyze images, recognize charts, and even caption visuals.
Benchmarks for vision instruction-tuned models are impressive:
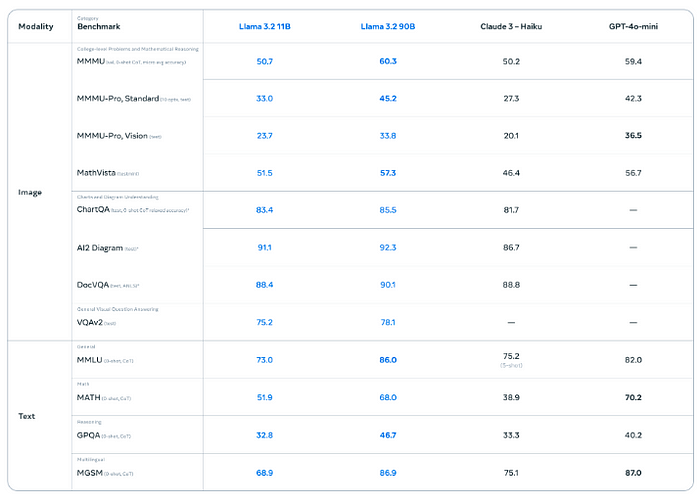
Plus, they’ve got these smaller, text-only models (1B and 3B) that fit right onto edge devices like mobile, and they’re surprisingly powerful for tasks like summarization, instruction-following, and more.
One of the coolest parts is Llama Stack, which makes working with these models a breeze whether you’re deploying on-prem, in the cloud, or on mobile.
They’ve even optimized everything for Qualcomm, MediaTek, and Arm hardware, so you can run it all locally if you want — super fast and private.
Let me walk you through a local development workflow that you can try now.
Let’s GO!

The Birth of Llama 3.2
Setting-up the environment for Llama 3.2-Vision and Ollama
llama3.2-vision requires Ollama 0.4.0, which is currently in pre-release, here’s how you can install it (from home directory):
curl -L https://github.com/ollama/ollama/releases/download/v0.4.0-rc6/ollama-linux-amd64.tgz -o ollama-040-rc6.tgz
sudo tar -C /usr -xzf ~/ollama-040-rc6.tgz
After installation is finished, you can check the installed version.
cd /usr/bin
./ollama --version

We can now start working with Llama 3.2-Vision model by running following command:
ollama run x/llama3.2-vision:11b
The 11 billion parameter model provides high accuracy in vision tasks, let’s see it in action.
Now let’s create a virutal environment and install required libraries.
mkdir llama32-ollama && cd llama32-ollama
python3 -m venv llama32-ollama-env
source llama32-ollama-env/bin/activate
pip3 install ollama
pip install pillow
pip3 install ipykernel jupyter
Great — to continue, you can either create .py file or .ipynb file (notebook). I will continue with Jupyter notebook to run code in blocks and interactively inspect the results.
Step 1: Importing Required Libraries
We begin by importing the libraries needed for image processing, base64 encoding, and interacting with the Llama 3.2 Vision model via ollama.
import base64
import io
from PIL import Image
import ollama
- base64 and io libraries handle image encoding.
- PIL.Image (from the Python Imaging Library) allows for opening and processing images.
- ollama provides the API to interact with the Llama 3.2 Vision model, which performs the OCR tasks.
Step 2: Encoding the Image to Base64
To send the image to the OCR model, we need to convert it into a base64 string format. This makes it easy to transmit the image data within API requests. Here’s the function to handle this process:
def encode_image_to_base64(image_path: str, format: str = "PNG") -> str:
"""Encodes an image file to a base64 string.
Args:
image_path (str): Path to the image file.
format (str): Format to save the image in memory (default is PNG).
Returns:
str: Base64-encoded image.
"""
with Image.open(image_path) as img:
buffered = io.BytesIO()
img.save(buffered, format=format)
return base64.b64encode(buffered.getvalue()).decode('utf-8')
- This function takes the image_path as input, loads the image, and saves it to an in-memory BytesIO buffer.
- We then encode the image bytes into a base64 string.
- The function defaults to saving in PNG format, which you can adjust as needed.
Next cohort will start soon! Reserve your spot for building full-stack GenAI SaaS applications
Step 3: Sending the Encoded Image to the OCR Model
With the image encoded in base64, we’re ready to interact with the Llama 3.2 Vision model to perform OCR. The function below sends the base64-encoded image along with a specific prompt and retrieves structured OCR output.
def get_ocr_output_from_image(image_base64: str, model: str = "x/llama3.2-vision:latest") -> str:
"""Sends an image to the Llama OCR model and returns structured text output.
Args:
image_base64 (str): Base64-encoded image string.
model (str): The model version to use for OCR (default is latest Llama 3.2 Vision).
Returns:
str: Extracted and structured text from the image.
"""
response = ollama.chat(
model=model,
messages=[{
"role": "user",
"content": "The image is a book cover. Output should be in this format - <Name of the Book>: <Name of the Author>. Do not output anything else",
"images": [image_base64]
}]
)
return response.get('message', {}).get('content', '').strip()
- We pass the base64-encoded image and instruct the model to output the book title and author in a specific format.
- Using .get() on nested dictionary keys ensures the code won’t throw an error if a key is missing.
- This function returns the structured OCR text, ready for use in further applications or display.
Next cohort will start soon! Reserve your spot for building full-stack GenAI SaaS applications
Step 4: Bringing It All Together in the Main Block
Finally, we set up a main block to use the functions we’ve created. This helps to keep the code modular and allows us to run it directly as a script:
if __name__ == "__main__":
image_path = 'examples/image.png' # Replace with your image path
base64_image = encode_image_to_base64(image_path)
ocr_text = get_ocr_output_from_image(base64_image)
print(ocr_text)
- Replace 'examples/image.png' with the path of your image.
- encode_image_to_base64 encodes the image, and get_ocr_output_from_image retrieves the structured OCR output, which we then print.
Here are some interesting examples to try:
- Documents and Receipts: Try scanning receipts, invoices, or documents where you need structured information like date, amount, or specific keywords.
- Handwritten Notes: Use images of handwritten notes or sticky notes, if the handwriting is legible. This will test the model’s ability to recognize non-standard fonts and handwriting.
- Signage and Billboards: Test images of street signs, billboards, or posters. These often have unique fonts or may be partially obstructed, which can be a good test of OCR precision.
- Product Labels: Snap images of product packaging or labels, especially with complex layouts (e.g., nutrition labels, ingredient lists), to see if it can accurately structure text from a detailed format.
- Magazine and Newspaper Covers: Use cover pages or headlines with mixed font sizes, bold text, or decorative elements to assess its flexibility with various visual styles.
Let us know what you find out in the comments!
Here’s the complete code:
import base64
import io
from PIL import Image
import ollama
def encode_image_to_base64(image_path: str, format: str = "PNG") -> str:
"""Encodes an image file to a base64 string.
Args:
image_path (str): Path to the image file.
format (str): Format to save the image in memory (default is PNG).
Returns:
str: Base64-encoded image.
"""
with Image.open(image_path) as img:
buffered = io.BytesIO()
img.save(buffered, format=format)
return base64.b64encode(buffered.getvalue()).decode('utf-8')
def get_ocr_output_from_image(image_base64: str, model: str = "x/llama3.2-vision:latest") -> str:
"""Sends an image to the Llama OCR model and returns structured text output.
Args:
image_base64 (str): Base64-encoded image string.
model (str): The model version to use for OCR (default is latest Llama 3.2 Vision).
Returns:
str: Extracted and structured text from the image.
"""
response = ollama.chat(
model=model,
messages=[{
"role": "user",
"content": "The image is a book cover. Output should be in this format - <Name of the Book>: <Name of the Author>. Do not output anything else",
"images": [image_base64]
}]
)
return response.get('message', {}).get('content', '').strip()
if __name__ == "__main__":
image_path = 'examples/image.png' # Replace with your image path
base64_image = encode_image_to_base64(image_path)
ocr_text = get_ocr_output_from_image(base64_image)
print(ocr_text)
Now, with Llama 3.2-Vision, you can handle everything in one go — analyzing the image, recognizing the text, and structuring the output — without needing to switch between multiple models.
This upgrade simplifies the workflow significantly, making it faster and more efficient.
Bonus Content : Building with AI
And don’t forget to have a look at some practitioner resources that we published recently: And don’t forget to have a look at some practitioner resources that we published recently:
Thank you for stopping by, and being an integral part of our community.
Happy building!