
Latest Vision, Image and Language Models: Pangea, Ferret, OmniParser, Granite, Pixtral, Aya, SD 3.5
2024-10-29
Recently, an influx of new model releases from all angles has felt like the floodgates of innovation bursting open.
Staying up-to-date might seem overwhelming — like drinking from a firehose — but rest assured, you’re in the right place.
I’ll guide you through the most groundbreaking developments you won’t want to miss:
- Pangea from CMU
- PUMA
- Ferret-UI from Apple
- OmniParser from Microsoft
- Pixtral 12B Base from Mistral
- Stable Diffusion 3.5 from StabilityAI
- Mochi from GenmoAI
- Granite 3.0 from IBM
- Llama 3.2 1B & 3B from Meta
- Aya Expanse from Cohere
Let’s GO!
Vision-Language Models
Pangea
Pangea-7B is an open-source multilingual multimodal large language model (MLLM) that delivers better performance than SoTA open-source models such as Llama 3.2 11B.
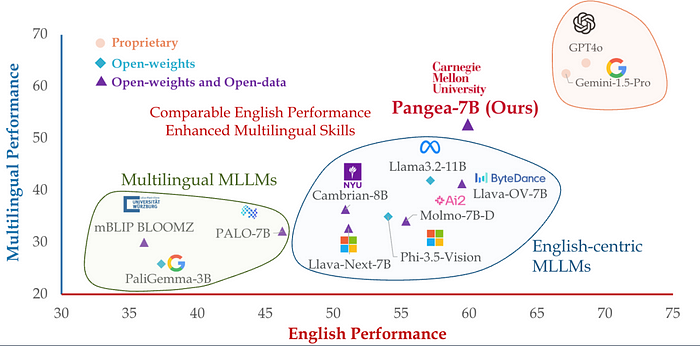
It’s designed to bridge not just language gaps but also cultural nuances in visual understanding tasks.
Pangea is powered by massive instruction tuning dataset called PangeaIns, containing 6 million samples across 39 languages.
PangeaIns includes general instructions, document and chart question answering, captioning, domain-specific, culturally relevant, and text-only instructions.
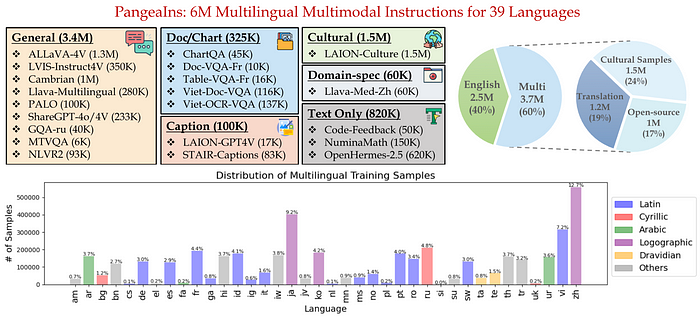
This isn’t also just machine-translated English data; they actually focused on including culturally relevant content. They even developed a pipeline to generate multicultural instructions and captions, ensuring the data isn’t just Anglo-centric.

These capabilities are important for global or multi-regional product development.
By leveraging Pangea-7B or its training techniques, you can significantly improve your product’s ability to handle multiple languages, both in text and image understanding.
This could be a differentiator in markets where cultural context is crucial for multimodal chat, captioning, multilingual VQA and multi-subject reasoning.
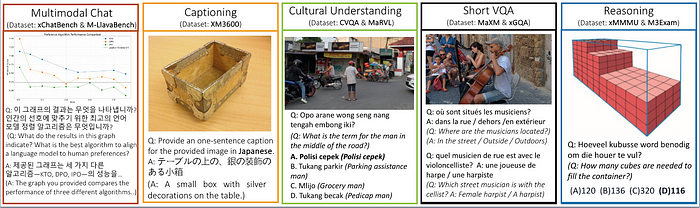
Here’s multilingual and multimodal benchmarks:
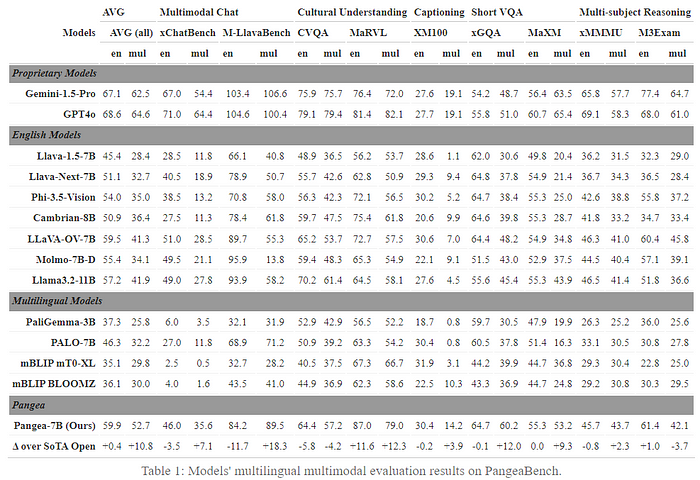
Pangea-7B, PangeaIns, and PangeaBench are open-source, you can directly experiment with them or integrate parts into your own models without starting from scratch.
Here’s the official page where you can find more information.
PUMA
Puma stands for “Powering Unified MLLM with Multi-grAnular visual generation” which aims to unify various visual generation and understanding tasks within a single Multimodal Large Language Model (MLLM).
The challenge it addresses is pretty significant: balancing diversity and controllability in image generation tasks.
- Diversity is crucial for tasks like text-to-image generation, where we want the model to produce a wide range of images that are semantically aligned with the input text.
- Controllability is essential for tasks like image editing or inpainting, where we need precise manipulation of images based on specific instructions.

PUMA introduces a multi-granular approach to visual feature representation to achieve this:
- Multi-Granular Visual Features: It extracts features at multiple levels of granularity from images. Think of it as capturing both the broad strokes and the fine details.
- Unified Framework: It processes and generates these multi-granular features within a single MLLM, allowing it to adapt to the requirements of different tasks seamlessly.
- Dedicated Decoders: It uses a set of diffusion-based decoders that can handle these multi-scale features to reconstruct or generate images.
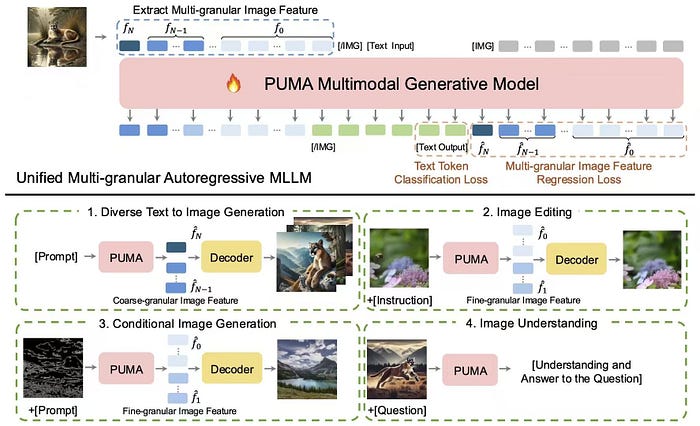
This is important because in previous models, there was often a trade-off:
- Models optimized for diversity lacked precise control.
- Models optimized for control produced less varied outputs.
PUMA overcomes this by handling multiple levels of detail simultaneously, allowing for both high diversity and precise controllability.
It provides diverse text-to-image generation, image editing, and conditional image generation.

Here are some of the technical highlights:
- Two-Stage Training Strategy: multimodal pretraining followed by task-specific instruction tuning.
- Efficient Architecture: relatively smaller image encoder (CLIP-Large with 0.3B parameters), making it resource-efficient.
- State-of-the-Art Results: superior performance across various benchmarks compared to existing models like SEED-LLaMA, SEED-X, and Emu2.
Refer to official page and paper for more information.
Ferret-UI from Apple
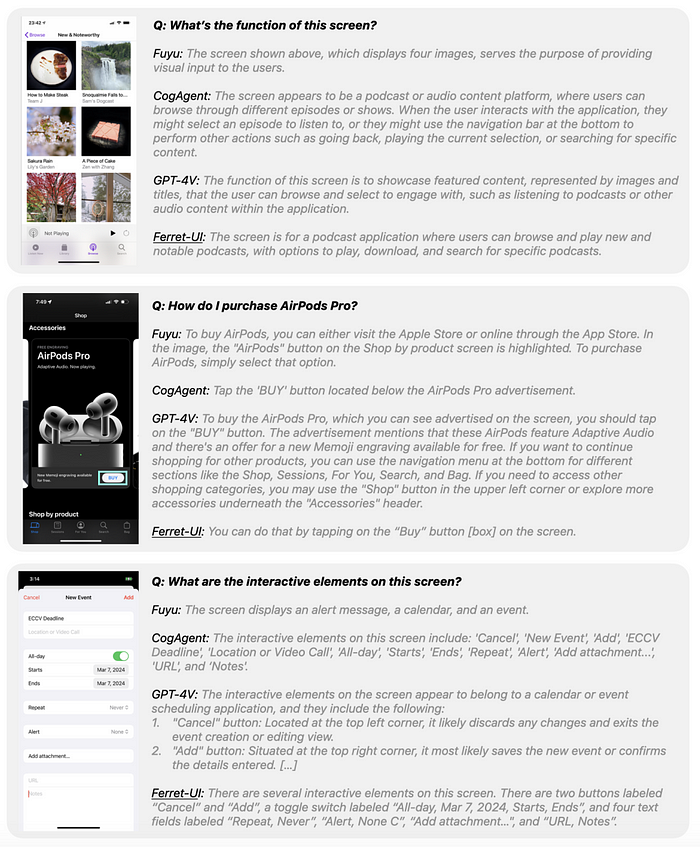
Multimodal large language models (MLLMs) like GPT-4V (the vision-enabled version of GPT-4) have made huge strides recently.
But despite their prowess with natural images, they often stumble when it comes to understanding and interacting with mobile user interface (UI) screens.
The problem is that UI screens are quite different from natural images — they have elongated aspect ratios and contain lots of tiny elements like icons and text, which standard MLLMs aren’t optimized for.
Ferret-UI is tailored specifically for mobile UI understanding. It’s built on top of the original Ferret model, which is known for its strong referring and grounding capabilities in natural images.
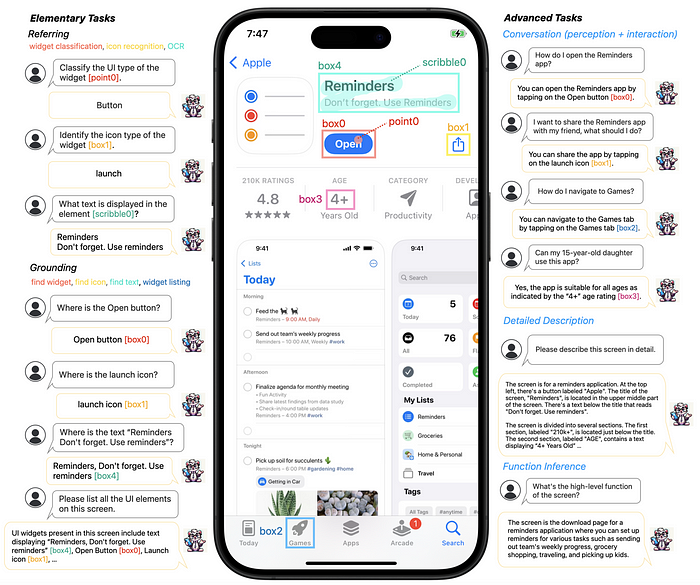
Ferret-UI is able to perform referring tasks (e.g., widget classification, icon recognition, OCR) with flexible input formats (point, box, scribble) and grounding tasks (e.g., find widget, find icon, find text, widget listing) on mobile UI screens… Ferret-UI is able to not only discuss visual elements in detailed description and perception conversation, but also propose goal-oriented actions in interaction conversation and deduce the overall function of the screen via function inference.
There are a few key innovations behind Ferret-UI:
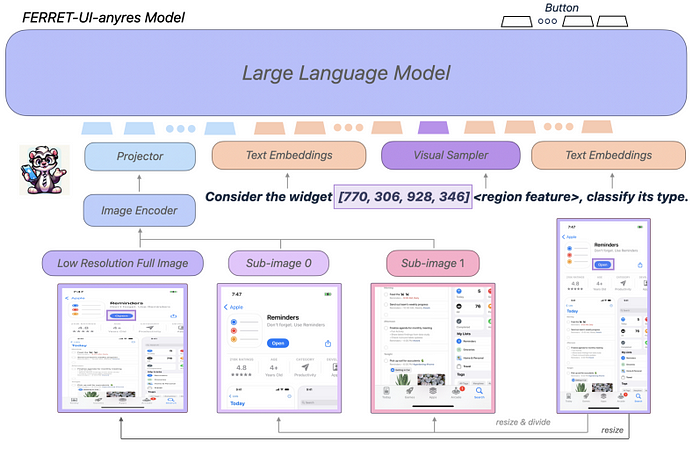
- “Any Resolution” Handling: To tackle the aspect ratio issue, they incorporated an “any resolution” approach. Essentially, they divide each screen into two sub-images based on its original aspect ratio — horizontally for portrait and vertically for landscape. These sub-images are then processed separately, which allows the model to capture finer details that would be lost if the screen were just resized to fit a standard input size.
- Enhanced Visual Features: By processing sub-images, Ferret-UI magnifies small UI elements, making it better at recognizing and interpreting icons, buttons, and text fields.
- Task-Specific Training Data: They didn’t just rely on general training data. Instead, they curated a comprehensive dataset focused on UI-specific tasks: (1) Elementary tasks such as icon recognition, text finding, widget listing, etc. (2) Advanced tasks such as detailed screen descriptions, perception and interaction conversations, function inference.
- Instruction-Following with Region Annotations: By formatting training samples with region annotations, the model learns to refer to and ground its understanding in specific parts of the UI, which is crucial for precise interaction.
Here’s why it is important from product development perspective:
- Improved UI Automation: With a model that understands UI screens at this level, we can build more intuitive automation tools. Imagine an AI that can navigate apps, make reservations, or fill out forms just like a human would, by truly understanding each UI element.
- Enhanced Accessibility: Ferret-UI’s capabilities could significantly aid users with disabilities by providing more accurate descriptions of screen content and enabling voice-controlled navigation.
- Better Customer Experience: For our GenAI-powered products, integrating such a model means users get a smoother, more intuitive experience. The AI can guide them through complex interfaces, anticipate their needs, and reduce the friction often associated with mobile apps.
There are also other potential applications:
- Multi-Step UI Navigation: Building assistants that can perform complex tasks across multiple screens.
- App Testing and Usability Studies: Automated testing tools that understand UI layouts can identify usability issues without human intervention.
- Personalized Interactions: Tailoring the UI experience based on user preferences detected by the AI.
I believe exploring this further could be really beneficial for your upcoming mobile projects.
You can find more information in Ferret-UI’s paper.
OmniParser from Microsoft
Coming back to the challenges that GPT-4V faces across user interfaces (UIs) across different platforms — like Windows, macOS, iOS, Android — and also various applications, there are 2 main things to understand:
- GPT-4V doesn’t reliably recognize which icons or buttons on a screen can be interacted with.
- GPT-4V has trouble grasping the function or meaning behind each UI element, making it hard to decide what action to take and where to execute it on the screen.
Without these capabilities, GPT-4V can’t effectively act as a general agent that can perform tasks across different apps and platforms.
Most of the existing solutions rely on additional data like HTML code or view hierarchies, which aren’t always available, especially in non-web environments.
OmniParser from Microsoft is a screen parsing tool for pure vision based GUI agents to bridge these gaps.
Here’s how it works:
- It can detect interactable regions (like buttons and icons) on the screen.
- It can generate functional descriptions of these detected icons. Think of it as giving each icon a little label like “Settings gear” or “Play button,” which adds semantic understanding.
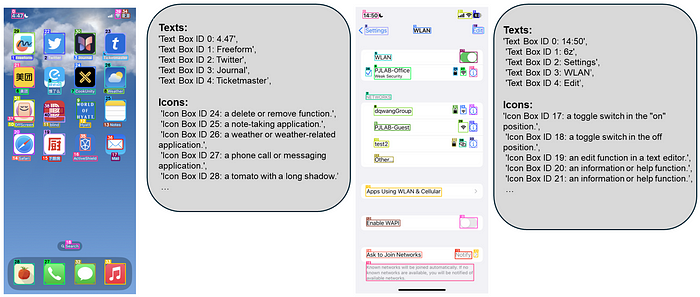
- It has OCR component to read any text on the screen, which is crucial for understanding labels, menu items, etc.
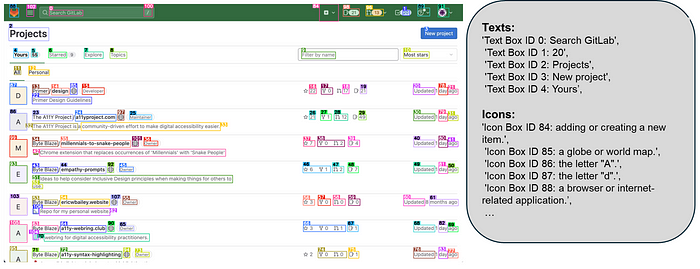
By combining these three components, OmniParser effectively turns a raw screenshot into a structured, DOM-like representation of the UI, complete with bounding boxes and semantic labels.
OmniParser is tested on several benchmarks like ScreenSpot, Mind2Web, and AITW, which cover various platforms and tasks. The results were pretty impressive:
- It improved GPT-4V’s performance compared to the baseline models that didn’t use this enhanced parsing.
- Even more interestingly, OMNIPARSER with just the screenshot as input outperformed other models that required additional information like HTML code or view hierarchies.
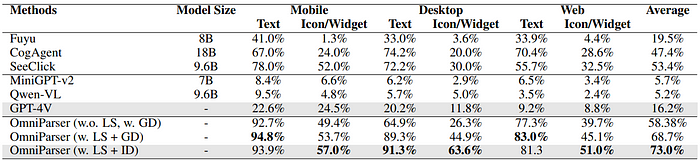
For us, this means we can develop AI agents that are much more adept at interacting with UIs across different platforms without relying on extra data that’s not always accessible.
However, there are still potential challenges:
- The model can get confused with repeated elements. To mitigate this, adding finer-grained descriptions or contextual information can help the model differentiate between them.
- Sometimes the bounding boxes aren’t precise enough. Combining OCR and interactable region detection might improve accuracy here.
- The icon description model might mislabel icons without context. Training the model to consider the full screen context can enhance its interpretations.
You can find more info on github, paper and blog post.
Next cohort will start soon! Reserve your spot for building full-stack GenAI SaaS applications !
Pixtral 12B Base from Mistral
Mistral’s latest release, Pixtral 12B, is something you should definitely know about.
It’s their first-ever multimodal model that’s open-sourced under the Apache 2.0 license, which is awesome because we can adapt and integrate it freely.
It’s trained to handle both images and text simultaneously. They’ve interleaved image and text data during training, so it excels in tasks that require understanding and reasoning over visual content alongside text. Think of tasks like chart and figure interpretation, document question answering, and even converting images to code
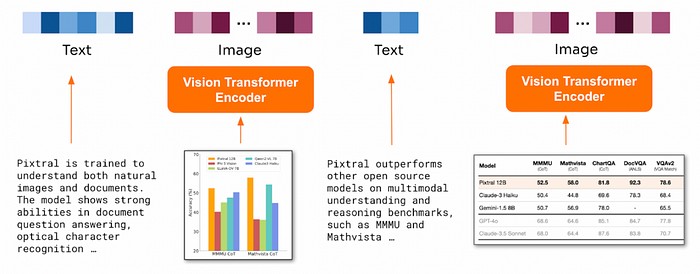
Performance-wise, it’s pretty impressive. On the MMMU reasoning benchmark, it scores 52.5%, outperforming some larger models. Plus, it maintains state-of-the-art performance on text-only benchmarks, so we’re not sacrificing text capabilities for the sake of multimodal prowess.
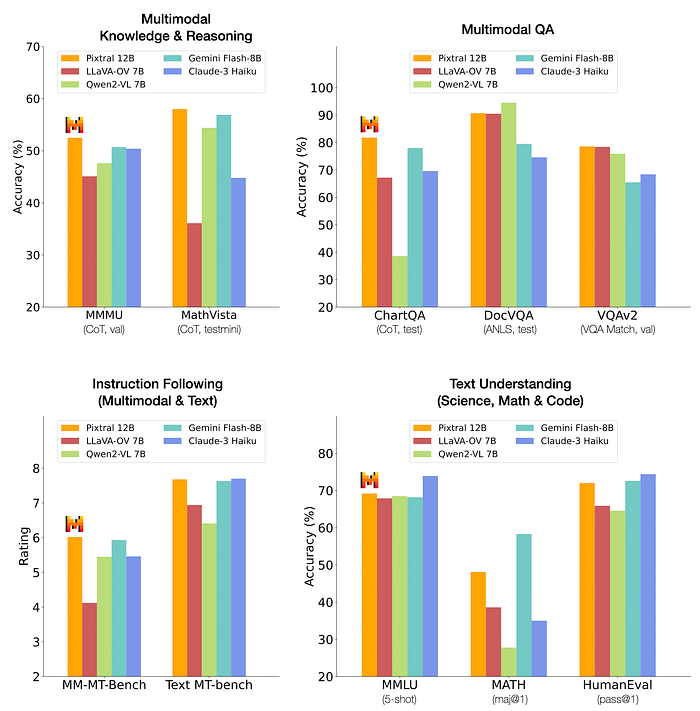
For starters, this could significantly enhance the customer experience in various products similar to other MLLMs.
For example:
- Visual Document Analysis: Users could upload PDFs or scanned documents, and the model could answer questions about them or extract key information.
- Chart and Figure Understanding: For analytics platforms, the model could interpret graphs and provide insights in natural language.
- Multimodal Assistants: Our AI could handle image inputs alongside text, making interactions more seamless and intuitive.
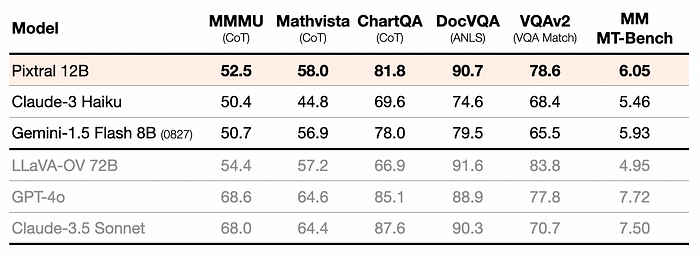
Pixtral substantially outperforms all open models around its scale and, in many cases, outperforms closed models such as Claude 3 Haiku. Pixtral even outperforms or matches the performance of much larger models like LLaVa OneVision 72B on multimodal benchmarks.All prompts will be open-sourced.
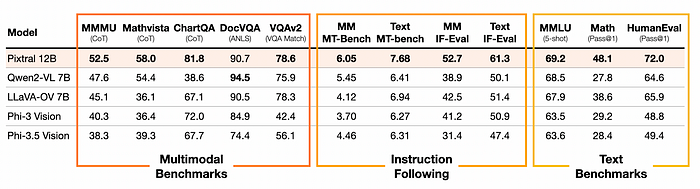
Instruction following is another area where Pixtral shines.
It outperforms other open-source models like Qwen2-VL 7B and LLaVa-OneVision 7B by a significant margin in both text and multimodal instruction following benchmarks.
This means it’s better at understanding and executing complex instructions, which is crucial for creating a smooth user experience.
Definitely read the official blog post and hugging face model card for more information.
Image and Video Generation Models
Stable Diffusion 3.5 from StabilityAI
No introduction needed for Stable Diffusion models!
Stability AI are soon releasing several models to cater to different needs:
- Stable Diffusion 3.5 Large: An 8 billion parameter model that offers superior image quality and prompt adherence. It’s their most powerful model yet, ideal for professional use cases at 1-megapixel resolution.
- Stable Diffusion 3.5 Large Turbo: A distilled version of the Large model. It generates high-quality images with exceptional prompt adherence in just 4 steps, making it significantly faster.
- Stable Diffusion 3.5 Medium (Coming October 29th): A 2.5 billion parameter model optimized for consumer hardware. It balances quality and ease of customization, capable of generating images between 0.25 and 2 megapixels. It outperforms other medium-sized models:
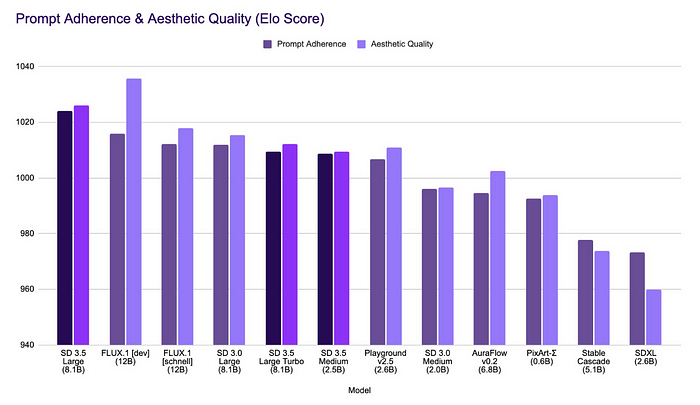
Here’s why these models matter:
- They’ve integrated Query-Key Normalization into the transformer blocks. This stabilizes training and simplifies fine-tuning, which means we will tailor the models to our specific needs more easily. Here’s the overview of all model components:
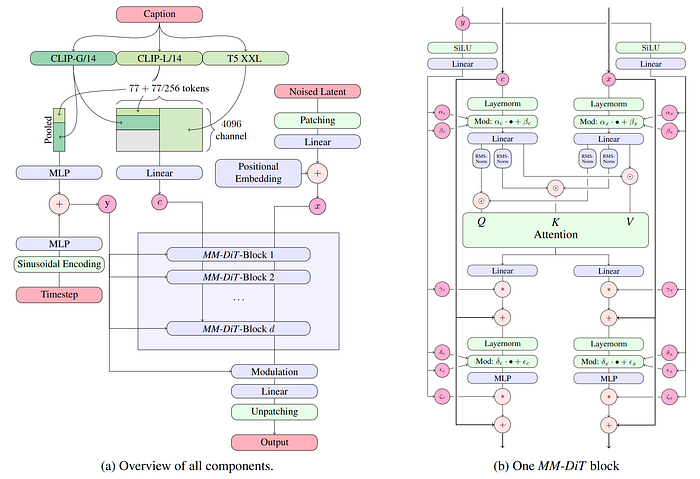
- Especially with the Medium and Large Turbo models, we can run these on standard consumer hardware. This will lower our infrastructure costs and make deployment more scalable.
- The models are designed to produce images that represent a wide range of styles, aesthetics, and subjects without needing extensive prompting. This will enhance our user experience by providing richer and more varied content.

Stable Diffusion 3.5 Medium release is set for October 29th, and shortly after the Medium model release, they’re launching ControlNets, which will offer advanced control features for a variety of professional use cases.
For more information, refer to official blog post, hugging face model cards and github.
Mochi from GenmoAI
Genmo has released a research preview of Mochi 1, and it looks great!
Mochi 1 is being touted as a new state-of-the-art (SOTA) in open-source video generation. It dramatically improves on two fronts that have been challenging for us: motion quality and prompt adherence.
It generates smooth videos at 30 frames per second for up to 5.4 seconds. The motion dynamics are so realistic that it’s starting to cross the uncanny valley. Think about simulating fluid dynamics, fur, hair, and human actions with high temporal coherence.

The model also shows exceptional alignment with textual prompts. This means when you feed it a description, the output video closely matches what you asked for. This level of control over characters, settings, and actions is something we’ve been wanting for a while.
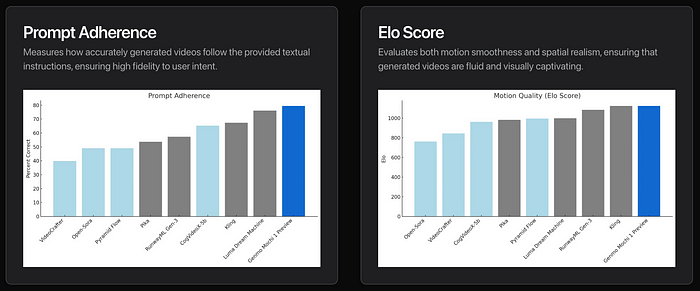
From product point of view, this opens up a lot of possibilities:
- With better prompt adherence and motion quality, you can offer users more accurate and engaging content — personalized videos that truly reflect user input without the jarring artifacts we’re used to seeing.
- The open-source nature (Apache 2.0 license) means you can integrate Mochi 1 into your projects without worrying about licensing issues. Plus, the code and weights are available on HuggingFace, so you can start tinkering right away.
- Mochi 1 uses a novel Asymmetric Diffusion Transformer (AsymmDiT) architecture, which is not just powerful but also efficient. They’ve also open-sourced their video VAE that compresses videos to a 128x smaller size. This is huge for resource management in production environments.

Here are some limitations to keep in mind:
- The initial release supports 480p videos. While that’s decent, they’re planning to release Mochi 1 HD later this year, which will support 720p.
- In scenarios with extreme motion, you might notice minor warping or distortions.
- Currently optimized for photorealistic styles, so it doesn’t perform as well with animated content.
You can find more information in official announcement.
Large Language Models
Granite 3.0 from IBM
Granite 3.0 is IBM’s latest generation of large language models, and they’re making a splash by releasing them under an Apache 2.0 license. That means they’re open-source and we can use them freely in our projects. They’ve trained these models on over 12 trillion tokens, covering 12 human languages and 116 programming languages. So, they’re pretty robust in terms of linguistic and coding capabilities.
Granite models support various languages such as English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, and Chinese.
Users may finetune Granite 3.0 models for languages beyond these 12 languages.
Granite models are designed to match top performance on general, enterprise, and safety benchmarks.
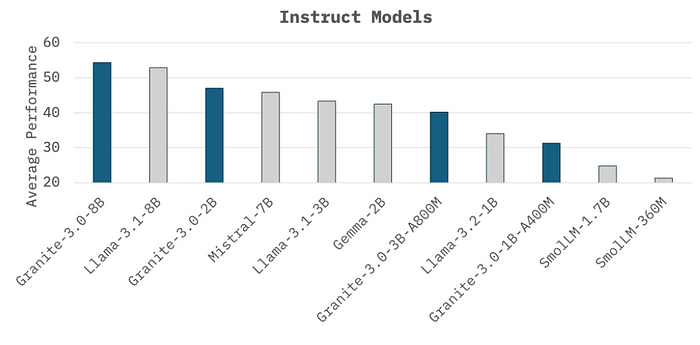
They can handle a variety of applications that are right up our alley:
- Summarization
- Text classification
- Text extraction
- Question-answering
- Retrieval Augmented Generation (RAG)
- Code related tasks
- Function-calling tasks
- Multilingual dialog use cases
Here’s how the Granite lineup breaks down:
- Granite Dense Models: These are the heavy lifters for enterprise AI. _Models_: Granite-3.0-8B-Instruct, Granite-3.0-8B-Base, Granite-3.0-2B-Instruct, Granite-3.0-2B-BaseThese are ideeal for tasks requiring strong general-purpose language understanding.
- Granite MoE (Mixture of Experts): These models are optimized for efficiency. _Models_: Granite-3.0-3B-A800M-Instruct, Granite-3.0-3B-A800M-Base, Granite-3.0-1B-A400M-Instruct, Granite-3.0-1B-A400M-Base.Great for on-device applications or CPU-based deployments where resources are limited.
- Granite Accelerator: This is a speculative decoding companion model. _Model_: Granite-3.0-8B-Instruct-AcceleratorDesigned to boost inference speed and reduce latency, which can significantly improve user experience.
Let’s also have a quick look at model hyperparameters:
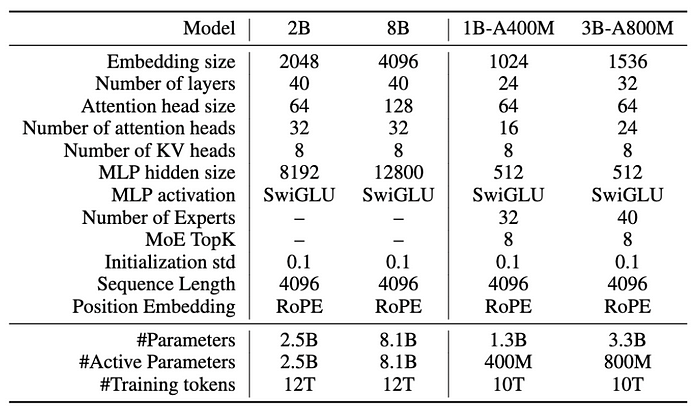
By the end of the year, they’re planning some major updates:
- Increasing from 4K to 128K tokens. This is huge for applications needing to process long documents or maintain extended conversations.
- Enabling key vision tasks, so we’ll be able to handle images along with text.
You can find more information on paper, blog, hugging face model cards and github.
Llama 3.2 1B & 3B from Meta
Meta has just released quantized versions of their Llama models — 3.2 1B and 3B — that are optimized for mobile and edge deployments.
Quantized models are significantly smaller and faster. We’re talking about a 2–4x speedup in inference time, an average 56% reduction in model size, and a 41% reduction in memory usage compared to the original models.
You can now deploy powerful LLMs directly on devices without hogging resources.
There are 2 key techniques used**:**
- Quantization-Aware Training with LoRA Adapters (QLoRA), where they simulated quantization effects during training. Essentially, they fine-tuned the model while it’s aware that it will be quantized, leading to better performance in low-precision environments.
- SpinQuant is a post-training quantization technique that’s all about portability. It doesn’t require access to the original training data, which is great when dealing with data privacy concerns. While it might be slightly less accurate than QLoRA, it’s incredibly flexible. You can take your already fine-tuned models and quantize them for different hardware targets, making deployment a breeze across various devices.
Here are some of the benchmarks that Meta shared for QLoRA and SpinQuant:
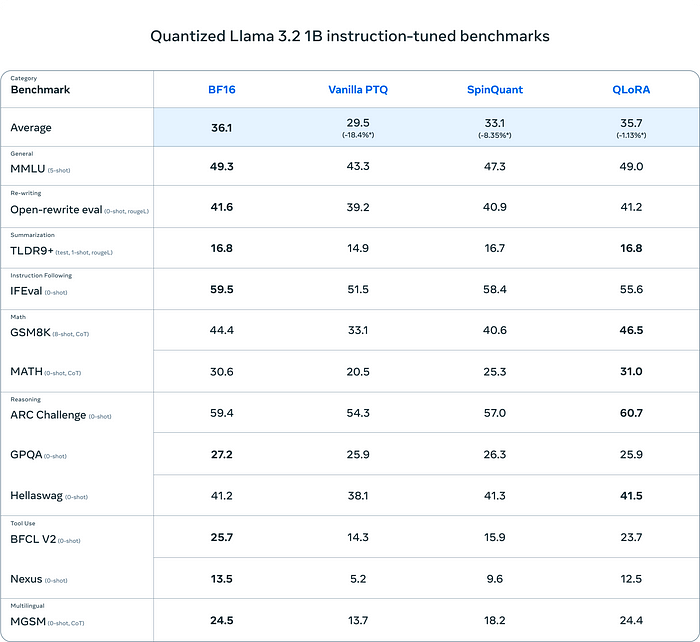
These are definitely great developments because,
- Running models on-device means faster response times and enhanced privacy since data doesn’t need to be sent to a server.
- With reduced model sizes and memory footprints, you can target devices with limited resources, broadening your user base.
- Less computational overhead can translate to lower operational costs, especially important for scaling your applications.
- Meta has made these models compatible with PyTorch’s ExecuTorch framework. So, integrating them into your workflow should be relatively straightforward.
More information on official blog post.
Aya Expanse
Big news from Cohere For AI!
They just released Aya Expanse, a family of top-performing multilingual models that’s raising the bar for language coverage.
Aya Expanse, available in both 8B and 32B parameter sizes, is open-weight and ready for you on Kaggle and Hugging Face.
The 8B model is designed to make advanced multilingual research more accessible, while the 32B model brings next-level capabilities across 23 languages.
The 8B version stands strong, outperforming its peers like Gemma 2 9B and Llama 3.1 8B with win rates ranging from 60.4% to 70.6%.
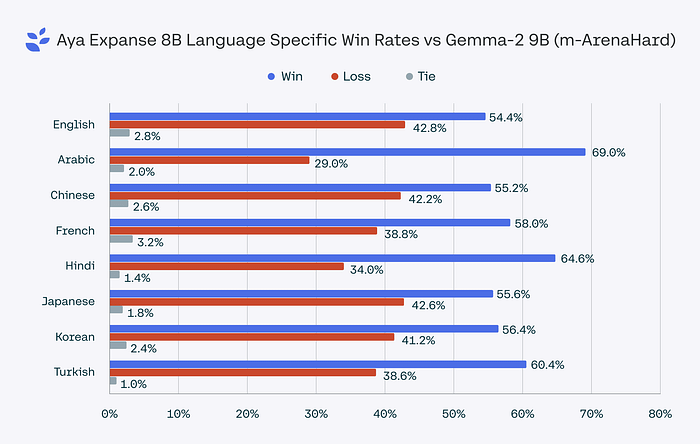
Aya Expanse isn’t just another model release.
Since the Aya initiative kicked off two years ago, Cohere has collaborated with 3,000+ researchers from 119 countries.
Along the way, they’ve created the Aya dataset collection (over 513 million examples!) and launched Aya-101, a multilingual powerhouse that supports 101 languages.
Cohere’s commitment to multilingual AI is serious, and Aya Expanse is the latest milestone.
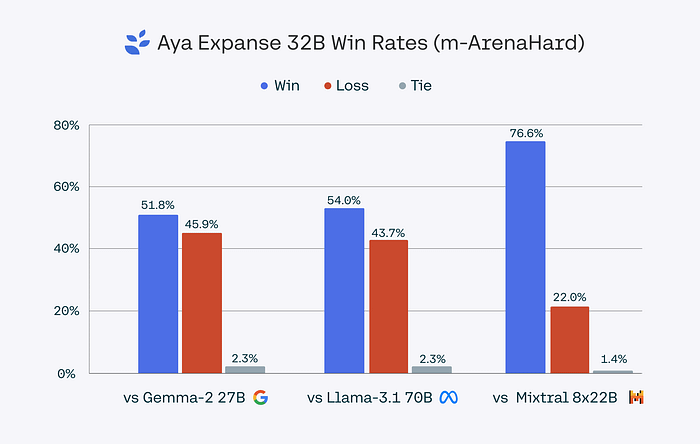
Aya Expanse 32B isn’t just another large model — it beats out others like Gemma 2 27B, Mistral 8x22B, and even the massive Llama 3.1 70B (that’s more than twice its size!) in multilingual tasks.
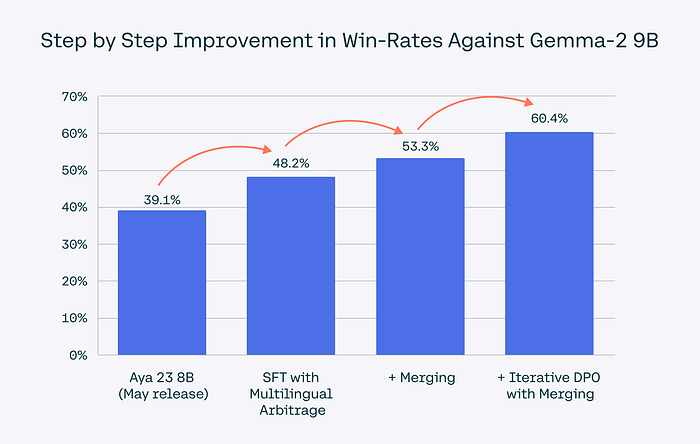
Here’s a sneak peek at the innovative approaches that power Aya Expanse:
- Data Arbitrage: Instead of letting synthetic data turn to “gibberish,” Cohere’s team designed a smart data sampling method called data arbitrage, using specialized “teacher” models for different languages to boost accuracy.
- Multilingual Preference Training: To make sure the models deliver quality and culturally appropriate responses, Cohere expanded preference training to 23 languages, creating a diverse safety and quality layer that reflects global perspectives, not just Western data.
- Model Merging: By merging weights from multiple models at each training stage, they’ve created models that adapt better across languages and deliver stronger performance.
Aya Expanse models are available now on the Cohere API, Kaggle, and Hugging Face, and you can already run it with Ollama!
- For 8B model run — ollama run aya-expanse
- For 32B model, run — ollama run aya-expanse:32b
You can find more information from official announcement.
That’s it folks — hope you enjoyed the read and start experimenting with some of these models in your applications.
And don’t forget to have a look at some practitioner resources that we published recently: