
Qwen2.5-Coder, Cosmos Tokenizer, OpenCoder, and New SentenceTransformers: Great Times for Open Source
2024-11-13
I want to highlight some standout open-source advancements that have really caught my eye:
- Qwen2.5-Coder Series: An open-source code LLM that’s giving GPT-4 a run for its money.
- Cosmos Tokenizer: An advanced suite of neural tokenizers for efficient image and video compression.
- OpenCoder: A fully open-source code LLM trained on an astonishing 2.5 trillion tokens.
- Massive CPU Speedup in SentenceTransformers: A 4x speed boost on CPU inference using OpenVINO’s int8 static quantization.
Let’s dive in!
Qwen2.5-Coder Series: Open-Sourcing a SOTA Code LLM Rivaling GPT-4
Alibaba Cloud announced the open-source release of the Qwen2.5-Coder series — models that are Powerful, Diverse, and Practical — dedicated to propelling the evolution of open code large language models (LLMs).
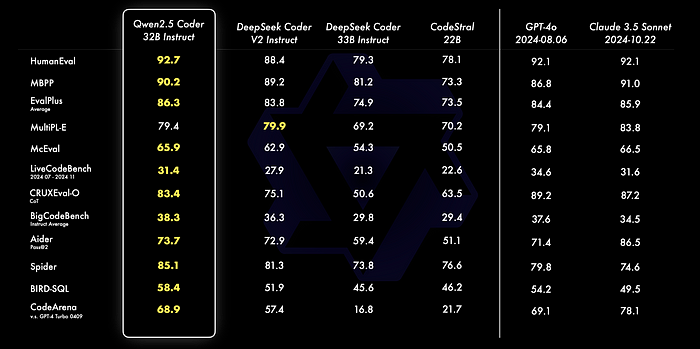
The flagship model, Qwen2.5-Coder-32B-Instruct, sets a new benchmark as the state-of-the-art (SOTA) open-source code model, matching the coding capabilities of GPT-4. It excels in general-purpose and mathematical reasoning.
Expanding upon previous releases of 1.5B and 7B models, they introduced four additional model sizes: 0.5B, 3B, 14B, and 32B. Qwen2.5-Coder now accommodates a wide spectrum of developer requirements, covering six mainstream model sizes.
They have also explored the applicability of Qwen2.5-Coder in real-world scenarios, including code assistants and artifact generation.
Practical examples highlight the model’s potential in enhancing developer productivity and code quality.
Benchmark Achievements
- Code Generation: The Qwen2.5-Coder-32B-Instruct model achieves top-tier performance on popular code generation benchmarks such as EvalPlus, LiveCodeBench, and BigCodeBench.
- Code Repair: Recognizing the importance of debugging in software development, Qwen2.5-Coder-32B-Instruct excels in code repair tasks. Scoring 73.7 on the Aider benchmark, it performs comparably to GPT-4, aiding developers in efficiently fixing code errors.
- Code Reasoning: The model exhibits advanced code reasoning abilities, learning code execution processes and accurately predicting inputs and outputs. Building upon the impressive performance of Qwen2.5-Coder-7B-Instruct, the 32B model further elevates reasoning capabilities.
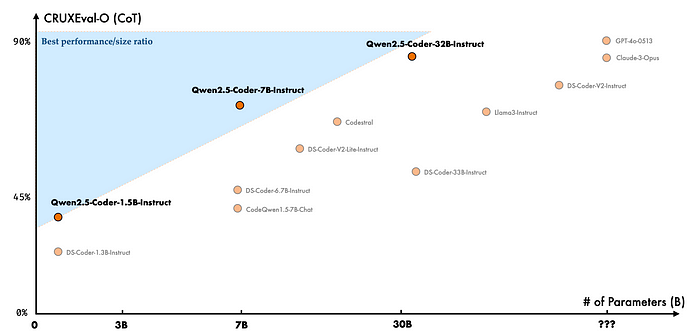
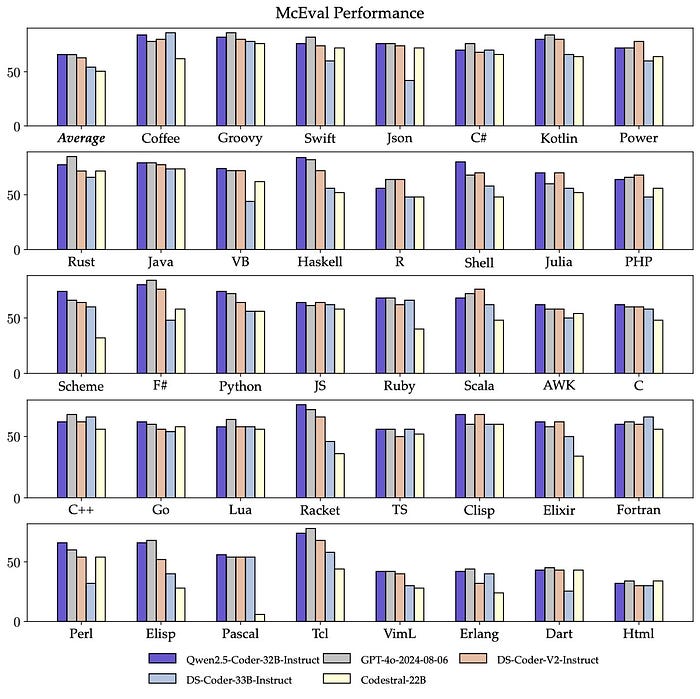
- Multi-Language Support: Qwen2.5-Coder-32B-Instruct is proficient in over 40 programming languages. It scores 65.9 on McEval, showing remarkable performance in languages like Haskell and Racket, thanks to unique data cleaning and balancing strategies during pre-training.
You can find more info on github.
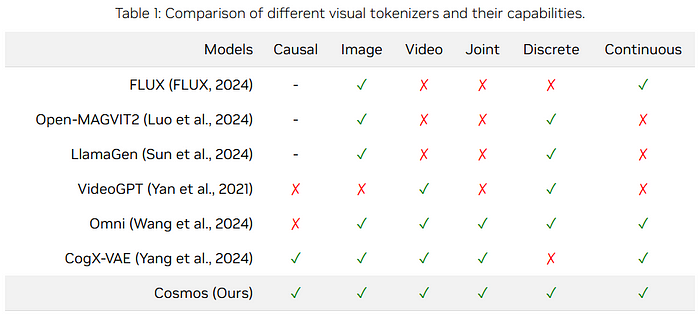
Cosmos Tokenizer: Advanced Neural Tokenizers for Efficient Image and Video Compression
The Cosmos Tokenizer is a comprehensive suite of neural tokenizers designed for images and videos.
You can now convert raw visual data into efficient, compressed representations.

By discovering latent spaces through unsupervised learning, these tokenizers facilitate large-scale model training and reduce computational demands during inference.
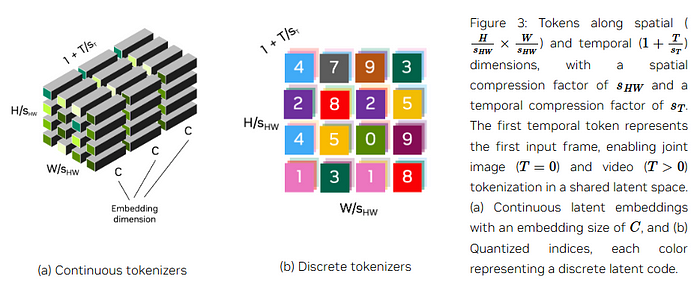
Types of Tokenizers:
- Continuous Tokenizers: Map visual data to continuous embeddings, suitable for models sampling from continuous distributions like Stable Diffusion.
- Discrete Tokenizers: Map visual data to quantized indices, used in models like VideoPoet that rely on cross-entropy loss for training.
Key Features:
- High Compression with Quality Preservation: Balances significant compression rates with high-quality reconstruction, preserving essential visual details in the latent space.
- Lightweight Temporally Causal Architecture: Utilizes causal temporal convolution and attention layers to maintain the chronological order of video frames, enabling seamless tokenization for both images and videos.
- Training on Diverse Data: Trained on high-resolution images and long videos across various aspect ratios and categories, making it agnostic to temporal length during inference.
Performance Highlights:
- Superior Compression Rates: Offers remarkable compression capabilities with speeds up to 12x faster than previous methods.
- High-Quality Reconstruction: Delivers significant gains in Peak Signal-to-Noise Ratio (PSNR), outperforming existing methods by over +4 dB on the DAVIS video dataset.
- Efficient Tokenization: Capable of encoding up to 8-second 1080p and 10-second 720p videos on NVIDIA A100 GPUs with 80GB memory.

Evaluation and Resources:
- TokenBench Dataset is a new dataset curated for standardizing video tokenizer evaluation, covering categories like robotics, driving, and sports.
- Public Availability: Pretrained models with spatial compressions of 8x and 16x, and temporal compressions of 4x and 8x, are available at [GitHub — NVIDIA/Cosmos-Tokenizer](https://github.com/NVIDIA/Cosmos-Tokenizer).
More information on NVIDIA’s official blog post.
Next cohort will start soon! Reserve your spot for building full-stack GenAI SaaS applications
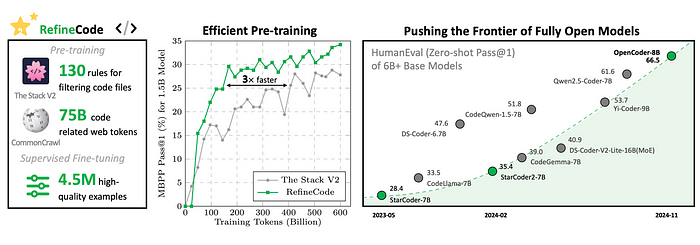
**OpenCoder: A Fully Open-Source Code LLM Trained on 2.5T Tokens**
OpenCoder introduces a new family of open-source code language models, including base and chat models at 1.5B and 8B parameter scales.
Supporting both English and Chinese languages, OpenCoder is trained from scratch on an extensive dataset of 2.5 trillion tokens, comprising 90% raw code and 10% code-related web data.
The model reaches performance levels comparable to leading code LLMs.
Key Contributions:
- The team provides model weights, inference code, training data, data processing pipelines, and detailed training protocols, empowering researchers and practitioners to build upon and innovate.
- They also introduced RefineCode dataset, a high-quality, reproducible code pre-training corpus containing 960 billion tokens across 607 programming languages.
More information on official announcement.
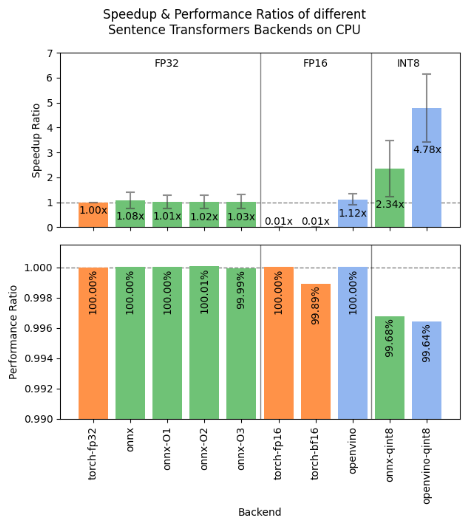
SentenceTransformers Accelerates CPU Inference with 4x Speed Boost
The latest release of SentenceTransformers introduces significant performance enhancements, delivering up to a 4x speedup on CPU inference using OpenVINO’s int8 static quantization.
This update optimizes both training and inference workflows for developers working with large-scale natural language processing tasks.
Key Enhancements:
- OpenVINO int8 Static Quantization: Leveraging OpenVINO’s quantization techniques, the model achieves superior inference speeds with minimal loss in accuracy. This optimization outperforms existing backends, enhancing deployment efficiency on CPU architectures.
- Prompt-Based Training: Supports training with prompts, offering a straightforward method for performance boosts without additional computational overhead.
- Convenient Evaluation on NanoBEIR: Facilitates quicker assessments of model performance using NanoBEIR, a subset of the robust Information Retrieval benchmark BEIR.
- PEFT Compatibility: Now supports Parameter-Efficient Fine-Tuning (PEFT) by allowing easy addition and loading of adapters, enabling more efficient model customization.
You can find more info on github.
Bonus Content : Building with AI
And don’t forget to have a look at some practitioner resources that we published recently:
Thank you for stopping by, and being an integral part of our community.
Happy building!