
LinkedIn’s Liger: The GPU Kernel Suite that Andrej Karpathy, Jeremy Howard, and Thomas Wolf Use for Efficient LLM Training
2024-08-25
LinkedIn just open-sourced a collection of Triton-based kernels that are specifically designed for Large Language Model (LLM) training.
Honestly, it’s kind of a big deal.
I will shortly explain why companies bother with custom kernels, but I didn’t see this coming for 2024, it’s going to save us lots of time!
By adding a single line of code, you can boost throughput by over 20% and cut memory usage by 60%.
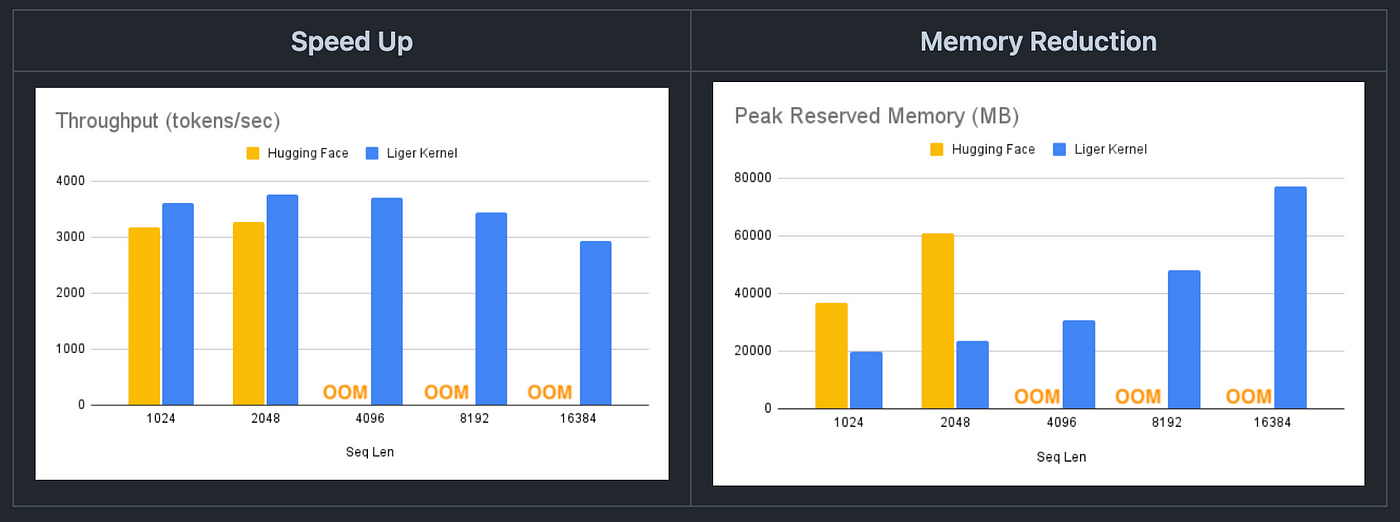
Benchmark conditions: LLaMA 3–8B, Batch Size = 8, Data Type = bf16, Optimizer = AdamW, Gradient Checkpointing = True, Distributed Strategy = FSDP1 on 8 A100s.
As you can see, Hugging Face models are out of memory at a 4K context length, whereas Hugging Face + Liger Kernel scales up to 16K.
This will effectively allow for extended context lengths, larger batch sizes, and support for extensive vocabularies.
Let’s dive deeper!

Hercules is a 10-year-old liger. He is 3.34m (11 feet) long and weighs 419 kg (922 lbs) which is more than 3 adult male African lions combined.
What’s the Buzz About Liger Kernels?
Liger Kernels, or as they officially call it, the LinkedIn GPU Efficient Runtime Kernel, are a set of custom Triton kernels that have been supercharged for LLM training.
We’re talking about a 20% boost in multi-GPU training speed and 60% reduction in memory usage.
This is great especially when LLMs can eat up resources like there’s no tomorrow.
Great part is that these kernels are incredibly easy to integrate into what you’re already doing.
They come with built-in support for key components we’re all using, like Hugging Face-compatible RMSNorm, RoPE, SwiGLU, CrossEntropy, and FusedLinearCrossEntropy.
Plus, they work right out of the box with tools like Flash Attention, PyTorch’s Fully Sharded Data Parallel (FSDP), and Microsoft DeepSpeed.
All it takes is adding one line of code, and you’re good to go.
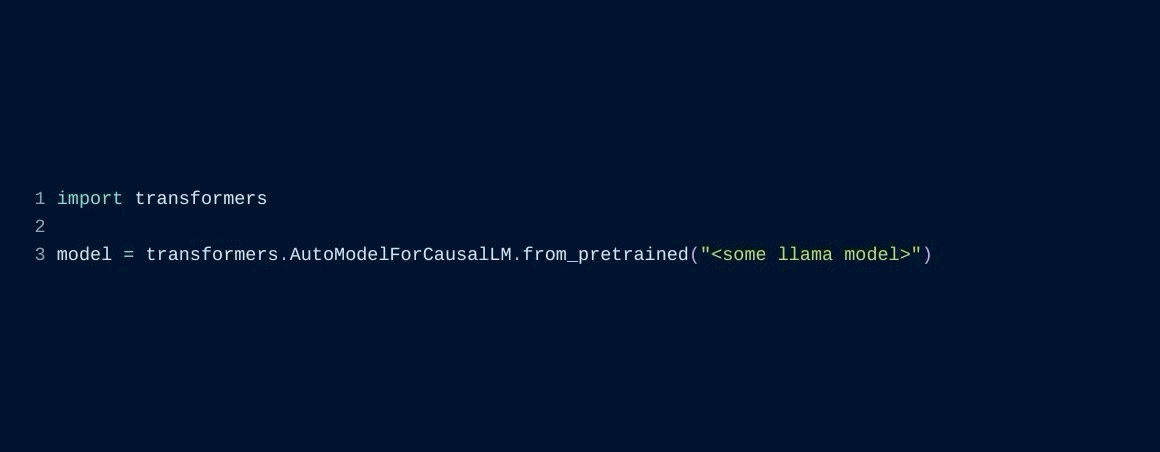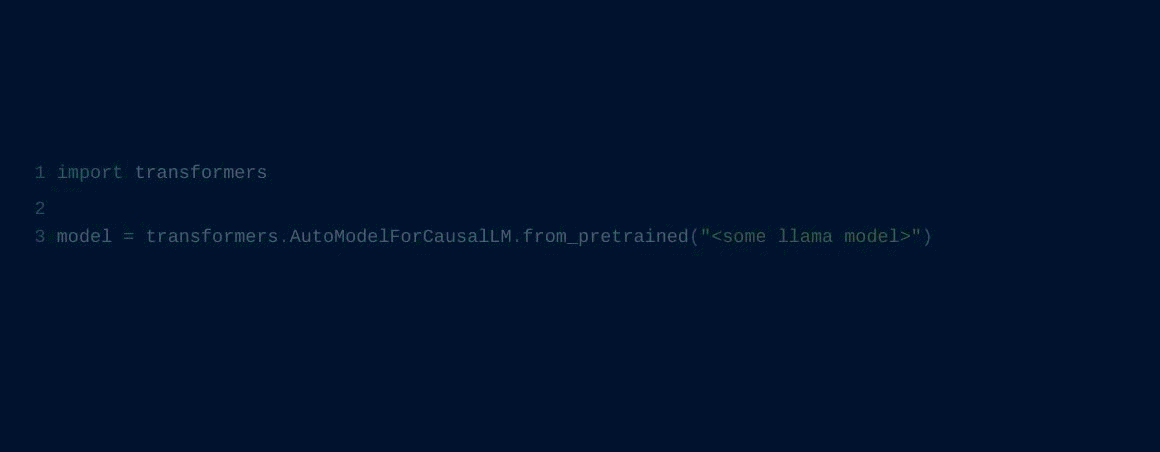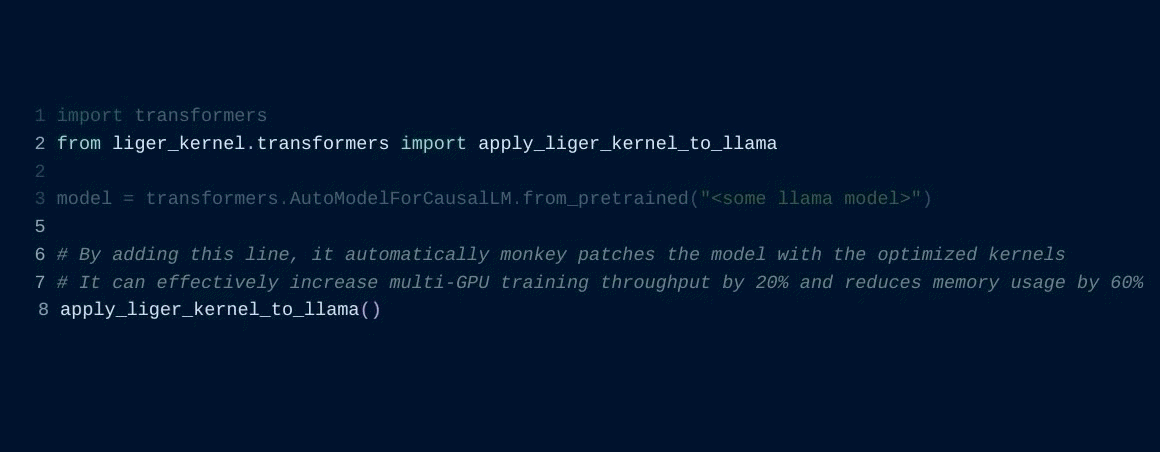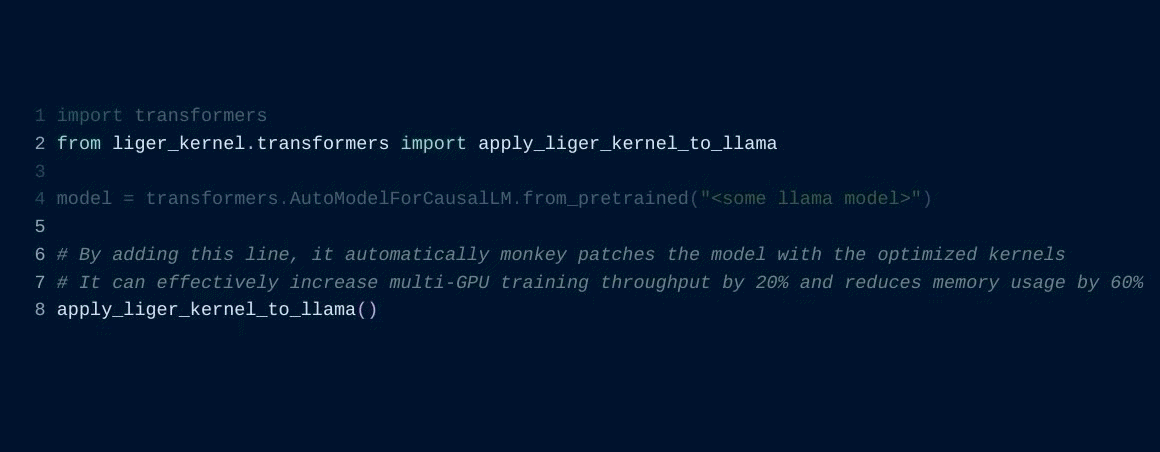
For example, with minimal modifications, you can train Llama 3 8b ~20% faster with over 40% memory using 4xA100s with FSDP.
The team ensured that computations are exact, with no shortcuts or approximations. Both forward and backward passes are rigorously tested, with unit tests and convergence testing against non-Liger Kernel training runs to guarantee accuracy.
Liger Kernel is also designed to be minimalistic, with only essential dependencies like Torch and Triton. No extra libraries are required, so you can say goodbye to dependency management headaches.
Also fully compatible with multi-GPU setups, including PyTorch FSDP, DeepSpeed, and DDP.
You can easily scale your training across multiple GPUs without hassle — here’s the usage:
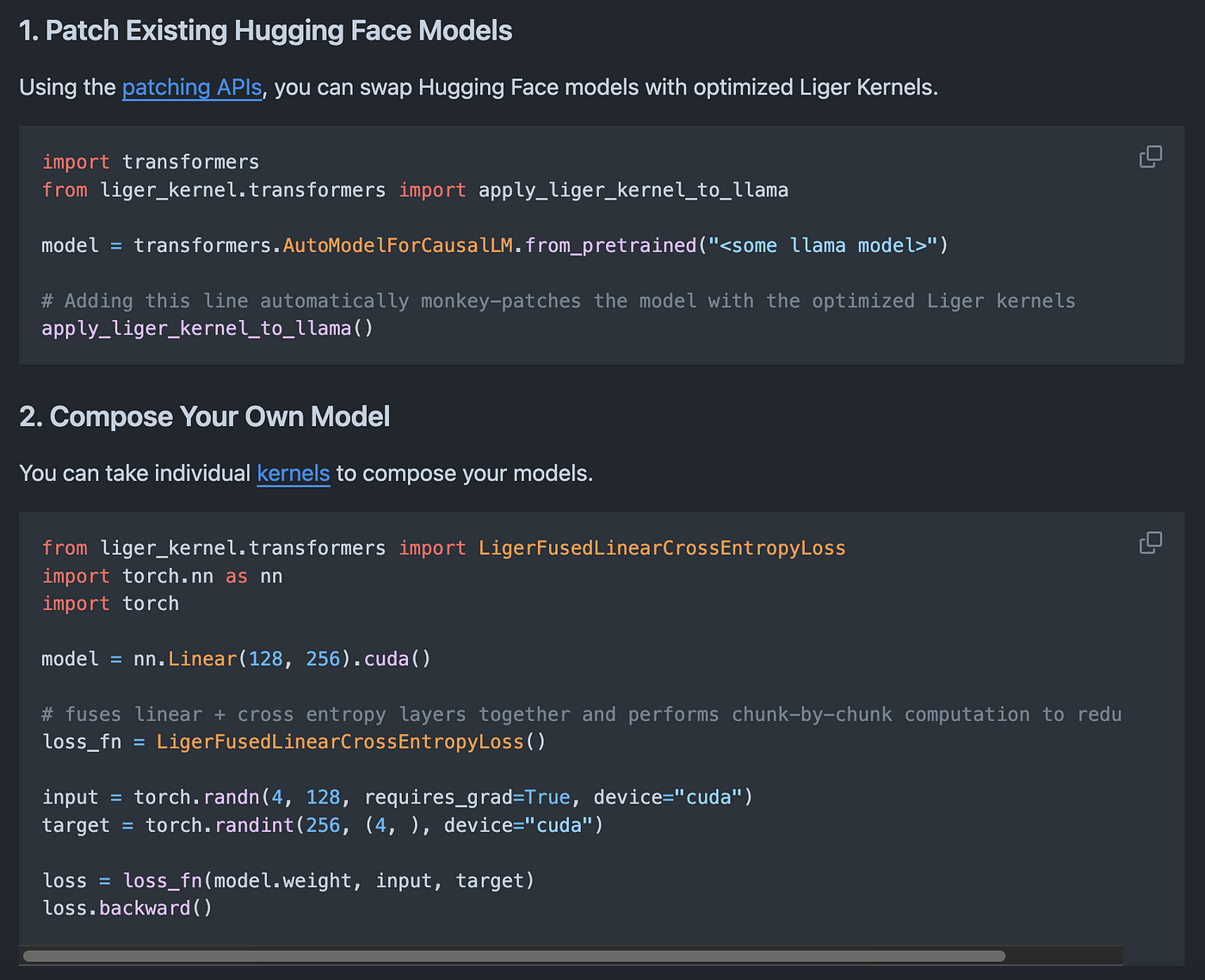
These features make it very ideal for researchers for building models with efficient, reliable kernels for experimentation.
Also perfect for engineers focused on maximizing GPU training efficiency using high-performance, optimized kernels.
And if you want to learn how all this works under the hood, it will also serve as agreat resource to learn how to develop reliable Triton kernels and improve training efficiency.
OK so the real question is, why develop a custom kernel at all?

Why Bother with Custom Kernels?
You might be thinking, “Why even bother with custom kernels when standard ones do the job?”
Great question and let’s break it down.
In LLM training, compute-bound operations like matrix multiplication are the heavy lifters — they account for over 99.8% of the FLOPs (floating point operations per second).
But those operations only make up 61% of the total runtime.
So, where’s the rest of the time going?
It’s getting chewed up by memory-bound operations like statistical normalization and element-wise functions.
These operations are slow because they involve a lot of back-and-forth between memory and computation, which creates a bottleneck.
This is where custom kernels like Liger come in and save the day.
By fusing these memory-bound operations together, you can dramatically reduce the time spent moving data around.
This means you get better bandwidth utilization and lower latency, which translates to faster and more efficient AI workloads.
It’s kind of like hitting the turbo button on your training process.

Triton: The Secret Sauce Behind Liger
Now, let’s talk about Triton because it’s the engine that makes all of this possible.
Triton is a language and compiler developed by OpenAI, and it’s all about making GPU kernel development more accessible.
It helps us navigate the complexities of GPU programming, making it easier to write efficient, high-performance kernels without needing to be a CUDA expert.
Back in the day, if you wanted to write a custom kernel, CUDA was your go-to.
But let’s be real — CUDA development isn’t exactly user-friendly. It requires deep C++ knowledge and a solid grasp of GPU architecture.
Before we continue, let me add a brief and kind request here:
Stay in the loop
You’re not just writing code; you’re optimizing every little detail, from memory management to thread concurrency.
For those of us who are more comfortable with Python, that’s a pretty steep hill to climb.
Triton changes the game by abstracting away a lot of that complexity. It lets you write custom GPU kernels in Python and work at a higher level — like, block level instead of thread level.
Triton handles all the low-level stuff like memory management and thread synchronization, so you don’t have to.
This makes kernel development way more accessible, and it also means your code is more portable across different GPU architectures.
So, no more spending hours tweaking things for every new piece of hardware.

What Liger Kernels Mean for Developers
There’s more to this than just the tech specs.
This release is also about taking control of our AI infrastructure.
Right now, a lot of companies rely heavily on cloud-based AI services, which can be great but also risky — you end up depending on someone else’s platform and roadmap.
With Liger Kernels, though, we’re in the driver’s seat.
We can customize and optimize our tools to fit our specific needs, without being tied to a particular vendor’s ecosystem.
It’s about having the freedom to innovate and adapt, which is pretty empowering.
And the community response to Liger Kernels has been amazing.
The GitHub repo shot up to 1.1K stars in just a few days, and big names like Andrej Karpathy and Thomas Wolf are already on board.
Teams are reporting some serious gains, like cutting training times from 15 hours to just 9.5 with these kernels.
That’s no small feat and really shows the kind of impact this can have.
Axolotl and Hugging Face Trainer already announced day-one support for Liger Kernel, and there’s talk about extending these optimizations to other areas, like vision models, which could open up even more possibilities.
LinkedIn releasing these kernels under a BSD license also shows they’re serious about community-driven innovation.
It’s not just about making a splash — they’re in it for the long haul, and they want all of us to be a part of it.

So, if you’re in the middle of a project, or just looking to experiment with something new, give Liger Kernels a try.
Here’s also some bonus content for you:
Thank you for stopping by, and being an integral part of our community.
Happy building!