
Llama 3.1 INT4 Quantization: Cut Costs by 75% Without Sacrificing Performance!
2024-08-14
This is a very important news for LLM practitioners, who have been working with large language models across various business and product use-cases.
Neuralmagic Team just hit a major milestone. They successfully quantized all the Llama 3.1 models to INT4, and here’s where it gets really exciting — this includes the massive 405B and 70B models, both of which are now rocking ~100% accuracy!
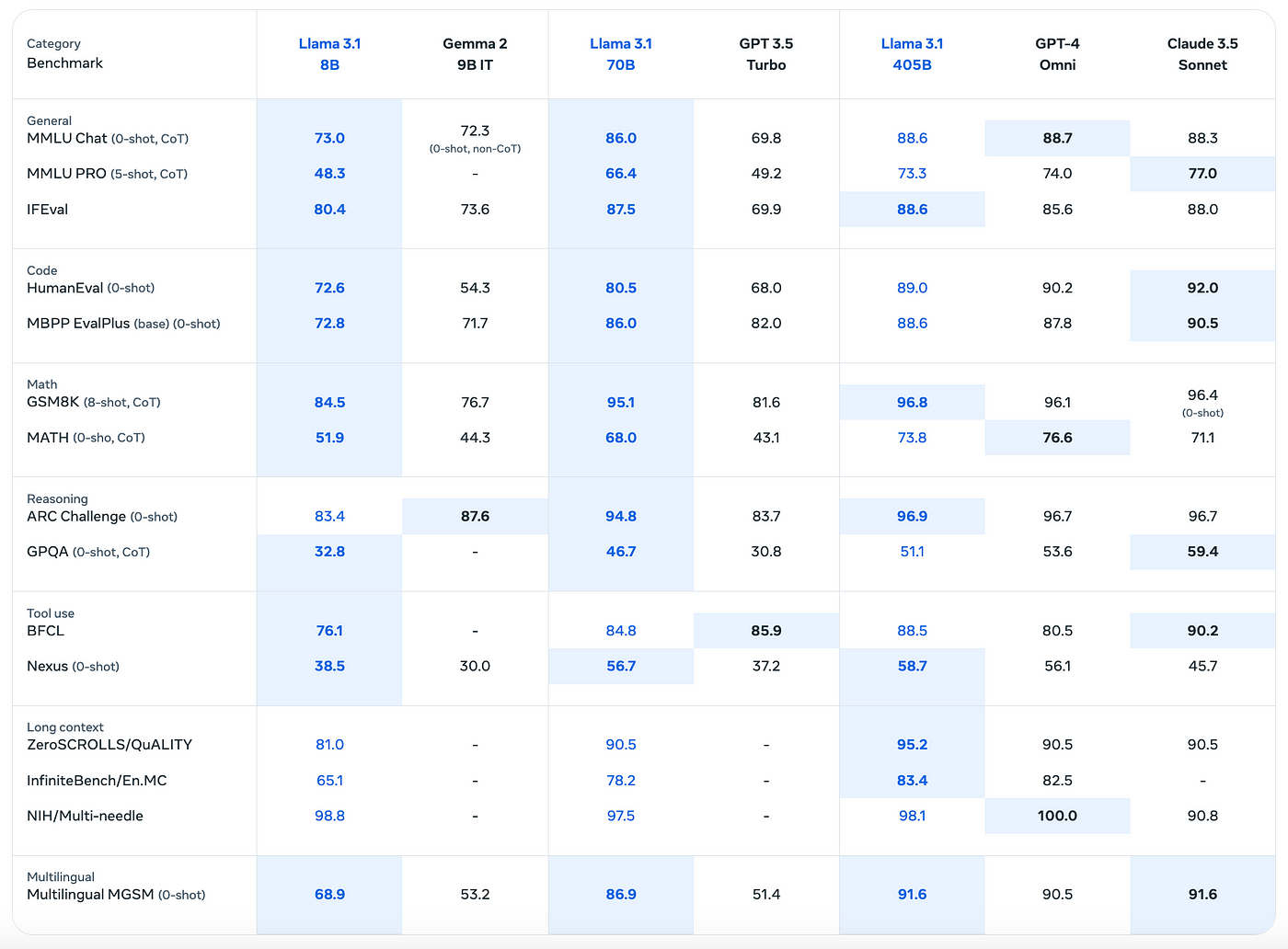
Llama 3.1 benchmarks against GPT-4, Gemma 2 and Claude 3.5 Sonnet
405B model, a beast that usually requires two 8x80GB GPU nodes, now can be run on a single server with just 4 GPUs — whether you’re working with A100s or H100s. That’s ~4x reduction in deployment cost! For those of us who’ve had to justify the resource demands of these large models, this is a huge win!
So, what’s the magic behind this? The team managed to quantize the weights of the Meta-Llama-3.1 models (405B, 70B, and 8B) to the INT4 data type. By shrinking the number of bits per parameter from 16 to 4, they managed to slashed the disk size and GPU memory requirements by about 75% without comprimising performance.
Llama 3.1: Tool use and multi-lingual agents
INT4 Performance
Let’s talk about the results:
- The INT4 version of the Meta-Llama-3.1–405B-Instruct model scores an average of 86.47 on the OpenLLM benchmark, just a hair below the original model’s 86.63.
- The 70B-Instruct model hits 78.54 compared to the unquantized 78.67.
- And even the 8B-Instruct model holds its own with a score of 67.57 against the original’s 69.32.
These tiny differences are more than acceptable when you consider the massive efficiency gains.
Llama 3.1: Complex reasoning and coding assistants
Quantization Process
The quantization process focuses on only the weights of the linear operators within transformers blocks.
Symmetric per-channel quantization is applied, in which a linear scaling per output dimension maps the INT4 and floating point representations of the quantized weights. The GPTQ algorithm is applied for quantization, as implemented in the AutoGPTQ library. GPTQ used a 1% damping factor and 512 sequences of 8,192 random tokens.
Hugging Face Model Cards
You can check out the models below with full evaluations and deployment instructions:
-> INT4 405B
-> INT4 70B
-> INT4 8B
-> Llama 3.1 quantized collection (FP8, INT8, INT4)
The team will publish performance benchmarks in coming days and a recap of their results and learnings, so stay tuned!
Bonus Content:Building with LLMs
And don’t forget to have a look at some practitioner resources that we published recently:
Thank you for stopping by, and being an integral part of our community.
Happy building!