
Is OpenAI’s o1 a Fine-Tuned Version of GPT-4o with Chain of Thought? Here’s How It Works
2024-09-15
There is a lot of speculation about OpenAI’s latest release, the o1-preview model, affectionately nicknamed “Strawberry”.
As it promises to redefine how we approach complex problem-solving in AI applications, it has sparked significant discussion and speculation within the developer community about its underlying architecture and capabilities.
Here’s its performance on Norway Mensa IQ test.
The test consists of 35 puzzles in the form of visual patterns that must be solved within a 25-minute time limit, and the results are interesting enough.
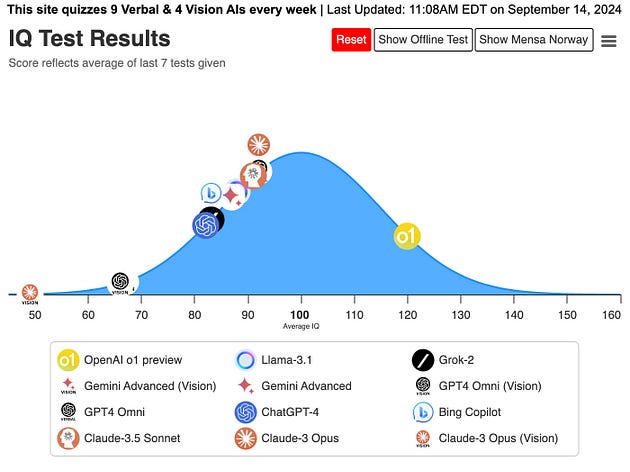 Source: Maxim Lott @maximlott on X — TrackingAI.org/IQ
Source: Maxim Lott @maximlott on X — TrackingAI.org/IQ
I believe o1 is the first reasoning model that excels at tackling challenging tasks, and it’s only going to improve from here.
I was watching and reading all week about the preliminary analysis that came from the community, here’s how it works.
At the end, I’ll share some papers for you to better understand o1, and also leave some practitioner resources for building with AI!

A Paradigm Shift in AI Reasoning
We know that traditional AI models often excel at pattern recognition and generating plausible text but falter when tasked with intricate reasoning.
The o1 model changes the game by simulating human-like thought processes.
Trained to spend more time thinking through problems, it refines its reasoning, tries multiple strategies, and recognizes mistakes before presenting a response.

This results in a model that doesn’t just provide answers — it understands problems at a deeper level.
Apart from useless puzzles, here’s some of the commentary that I actually find useful:
I spent ages bouncing back and forth between 4o and sonett 3.5 to build scraping tools for competitor websites, and only got them to mostly work, this afternoon with o1 fixed them — and combined them all into one and fixed all of the data alignment in about 15 minutes.
and another one:
I’ve had really good success using o1 for coding. Before o1, I had to do a lot of hand-holding, constantly managing context as it would drift and produce garbage. It would take 1–5 correction prompts to get it right. With o1, I can solve most of my problems zero-shot.
last one:
It’s also very good at providing the full code And it doesn’t break features when implementing new stuff
At least rarely
In my tests, it also seems to understand longer contexts, and tasks that involves more than 4 or 5 steps.
People have speculated that o1 achieves this through advanced techniques such as Chain-of-Thought (CoT) or Tree-of-Thoughts (ToT) frameworks, where the model internally reasons step-by-step.
There is also talk of the model employing an “inner monologue”, using special tokens or tags to indicate when deeper reasoning is required.
This could involve the model emitting a <thinking> tag to trigger additional processing or engage different sub-models.
If you already played with it, you can see several key components:
- Using Templated Chains-of-Thought: Guiding reasoning through structured prompts.
- Generalizing Policies: Handling a variety of problems with adaptable strategies.
- Ground-Truthing Processes: Improving reasoning rather than relying solely on memorized knowledge.
Even with all its advancements, it’s important to recognize that o1 isn’t a miracle model that outperforms previous versions in every aspect. If you’re expecting it to excel universally, you might end up disappointed.
Speculation on Multi-Model Architecture
There is also a possibility of o1 utilizing a multi-model architecture.
This could involve multiple models working together — a generator, a reasoner, and an evaluator — to produce and assess candidate solutions before presenting the final answer.
Such an approach would allow the model to generate diverse possibilities and select the most appropriate one, enhancing its reasoning capabilities.
Superior Performance on Complex Tasks
In rigorous testing, OpenAI reported that o1 model has demonstrated remarkable capabilities:
- Mathematics: Scored 83% on qualifying exams for the International Mathematics Olympiad (IMO), a significant leap from GPT-4o’s 13%.
- Coding: Reached the 89th percentile in Codeforces competitions, showcasing its proficiency in handling complex programming challenges.
- Sciences: Performed on par with PhD students in physics, chemistry, and biology benchmarks.
These advancements suggest that o1 might be trained on synthetic datasets specifically designed for reasoning tasks, improving its ability to handle complex problems in areas like math and code.
For developers, this means we can now build applications that handle complex reasoning tasks with greater accuracy.
I believe that every white-collar role will require individuals to work with a fine-tuned large language or multimodal model.
There are infinite number of SaaS products to build.
Whether it’s developing AI assistants for scientific research, creating advanced coding tools, or solving intricate mathematical problems, the models like o1 will provide a robust foundation.
Such models’ ability to simulate human-like reasoning will change how we approach problem-solving in AI applications.
By also potentially leveraging multi-phase generation, where the model goes through setup, generation, and conclusion phases, models will be able to explore multiple solutions before selecting the best one.

Improved Accuracy and Reliability
One of the longstanding challenges with AI models is the issue of “hallucinations” — instances where the AI generates incorrect or nonsensical information.
The o1 model addresses this by dedicating more processing power to verifying and refining its responses, significantly reducing errors.
This may involve scoring and selecting reasoning paths, where the model evaluates each step in its reasoning process and chooses the most accurate pathway.
Such methods could include policy models or actor-critic approaches to rank and select the best chain-of-thought.
This leads to:
- Enhanced User Trust: Users can rely on the AI’s responses, knowing they are more accurate.
- Reduced Need for Human Oversight: Less time spent correcting AI-generated errors means more efficient workflows.
Efficient Use of Computational Resources
Interestingly, the o1 model suggests a future where we can achieve superior reasoning without exponentially increasing model size.
By focusing on inference-time computation rather than just scaling up parameters, we can develop smaller, more efficient models that still outperform larger counterparts on complex tasks.
The model’s shift towards increased computation during inference allows it to perform more complex reasoning by effectively “thinking” through problems using multiple strategies before responding.
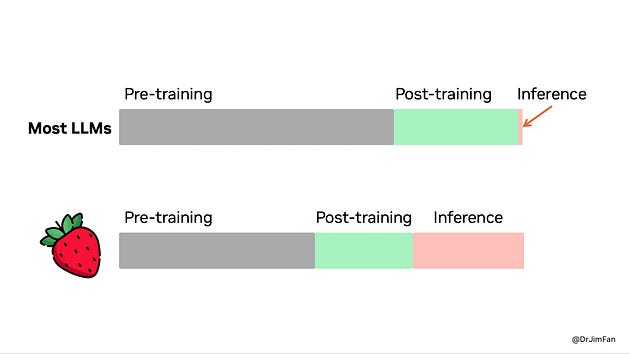
Source: Jim Fan @DrJimFan on X
This has several benefits:
- Cost-Effective Deployment: Reduced need for extensive pre-training compute lowers development costs.
- Scalability: Easier to deploy across various platforms and devices, including those with limited resources.
However, it’s important to note that while this approach enhances reasoning capabilities, it may lead to increased computational costs and latency during inference, which developers need to consider in deployment.
Stay in the loop
Personalized and Intelligent Interactions
With enhanced reasoning capabilities, first line of impact will be in AI-driven customer service platforms, which can provide more nuanced and helpful responses.
This will change how businesses interact with customers:
- Complex Query Resolution: Handle intricate customer inquiries without escalating to human agents.
- Proactive Problem-Solving: Anticipate customer needs by understanding context and subtleties in communication.
It will also lead to innovative applications across various domains:
- Healthcare: Assist in annotating cell sequencing data or analyzing complex medical information.
- Science and Engineering: Generate complicated mathematical formulas or simulate scientific phenomena.
- Education: Develop intelligent tutoring systems that can explain complex concepts in understandable terms.
The model’s potential integration with external tools and systems, such as code interpreters or search engines, could further enhance its capabilities, allowing it to access up-to-date information and perform specific tasks.

Enhanced Safety and Compliance
OpenAI has implemented a new safety training approach that allows the o1 model to better adhere to safety and alignment guidelines.
This is crucial for applications where compliance and ethical considerations are paramount.
The model now has an improved ability to avoid generating disallowed or harmful content, significantly reducing the risk of inappropriate outputs.
It also becomes easier to ensure that AI applications meet industry-specific compliance standards, aligning more closely with regulations.
By being able to reason about safety rules in context, the model can apply them more effectively, even when users attempt to bypass them through “jailbreaking.”
Embracing Inference-Time Compute Scaling
As mentioned, the o1 model introduces the practical scaling of compute during inference, not just during training.
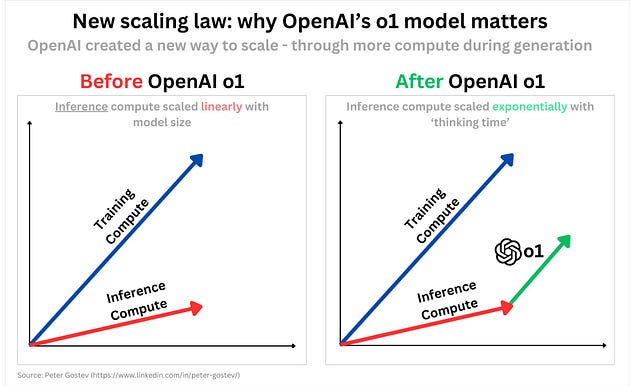
For developers, this means an opportunity for innovation by exploring new methods of problem-solving through leveraging inference-time computation.
There’s also the potential to utilize specialized hardware optimized for inference compute, opening doors for collaboration with vendors who focus on this area.
Increased demands during inference will lead to greater competition and innovation within the hardware space.
Focus on Search Over Memorization
The o1 model also exemplifies how search and reasoning can outperform mere memorization.
Allocating computational resources more effectively by focusing on reasoning processes leads to better resource optimization.
This approach emphasizes the importance of reasoning over knowledge recall.
It suggests that a smaller “reasoning core” can be more effective when combined with tools like browsers or code verifiers to access necessary information.
Increased Computational Cost and Latency
The enhanced reasoning requires more compute at inference time, potentially leading to higher operational costs.
More processing time can result in slower responses, which may not be suitable for all applications.
Implementing the model in production environments may require addressing issues like:
- Determining Search Depth: Deciding how extensively the model should explore possible solutions.
- Setting Success Criteria: Defining clear goals for the model’s reasoning process.
- Managing External Tool Integrations: Orchestrating when and how the model should use additional tools or resources.
These complexities necessitate careful planning and possibly new infrastructure to support the model’s advanced capabilities.
Past attempts at inducing advanced reasoning were often limited and inconsistent.
Ensuring that the o1 model provides consistent and reliable outputs across various tasks remains a challenge that developers need to address.
As community already highlighted, the o1 model might involve a complex architecture with multiple models interacting.
Developers need to consider whether the increased complexity justifies the performance gains and how to optimize the model for their specific use cases.
Regardless, OpenAI’s o1 model represents a significant milestone in AI development.
It offers a powerful tool to build applications that can reason, understand, and solve complex problems like never before.
Research Papers to Understand o1’s Internal Mechanics
If you want to dig deeper into the research, here are 5 papers that you can have a look at:
-> Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
-> Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning
-> Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
Bonus Content : Building with AI
And don’t forget to have a look at some practitioner resources that we published recently:
Thank you for stopping by, and being an integral part of our community.